Explain详解与索引最佳实践
Explain工具介绍id列select_typetable列type列Extra列索引的最佳实践索引的全值匹配最左前缀不在索引列上做任何操作尽量使用覆盖索引(只访问索引的查询(索引列包含查询列)),减少 select * 语句字符串不加单引号索引失效索引使用总结
Explain是MySQL的一个关键字,用于分析查询语句的执行计划。通过执行Explain命令,可以查看MySQL是如何执行查询语句的,以及MySQL是如何使用索引、连接表等技术来提高查询性能的。
Explain输出的执行计划是一个表格,包含多个列,每个列表示不同的执行信息。以下是Explain输出的一些重要列:
id:查询执行的顺序,如果id相同,则表示该查询在同一级别执行。select_type:查询类型,表示该查询是简单查询、联合查询、子查询等。table:该行数据来自哪个表。partitions:表示该查询使用哪个分区。type:表示MySQL使用哪种方式来查询数据,例如全表扫描、索引扫描等。possible_keys:表示MySQL可能使用哪些索引来执行查询。key:表示MySQL实际使用哪个索引来执行查询。rows:表示MySQL需要扫描多少行数据。Extra:提供额外的执行信息,例如使用了临时表、使用了文件排序等。
通过分析Explain输出的执行计划,可以找到查询语句的瓶颈,并且采取相应的优化措施。例如,如果Explain显示查询使用了全表扫描,那么可以尝试添加索引来加速查询。如果Explain显示查询使用了临时表,那么可以尝试优化查询语句,避免使用临时表。
在MySQL的Explain输出中,id列表示查询执行的顺序。对于一个查询语句,MySQL会将其转化为一个执行计划,该执行计划由多个查询操作组成,每个查询操作都有一个唯一的id号。执行计划中的每个查询操作都有一个id号,该号码是一个整数,用于表示该查询操作在执行计划中的位置。
id列是Explain输出中的一个非常重要的列,因为它提供了查询操作执行顺序的信息。在执行查询操作时,MySQL会按照id列中的顺序逐个执行每个查询操作,直到完成整个查询语句。
id列中的值越小,表示该查询操作越先执行。如果两个查询操作具有相同的id号,则它们在同一级别执行。在执行计划中,id列的值越小,表示查询执行的越早,因此较小的id号通常是优化查询性能的关键所在。
通常情况下,id列的值应该按照以下原则进行安排:
先执行子查询,然后再执行主查询。对于多表查询,应该先执行最具限制性的表。尽可能地使用索引来加速查询操作。
select_type列表示查询类型,用于表示该查询是简单查询、联合查询、子查询等类型。
select_type列的取值及其含义如下:
SIMPLE:表示查询中没有子查询或者UNION操作。PRIMARY:表示查询中最外层的查询。UNION:表示查询中的UNION操作。DEPENDENT UNION:表示查询中的UNION操作,但是UNION操作依赖于外部查询的结果。UNION RESULT:表示UNION查询中的结果集。SUBQUERY:表示查询中的子查询。DEPENDENT SUBQUERY:表示查询中的子查询,但是子查询依赖于外部查询的结果。DERIVED:表示查询中的派生表,即临时表。MATERIALIZED:表示查询中的物化子查询,即使用临时表来存储子查询结果集。UNCACHEABLE SUBQUERY:表示查询中的子查询不能被缓存。
当 from 子句中有子查询时,table列是 格式,表示当前查询依赖 id=N 的查询,于是先执行 id=N 的查询。 当有 union 时,UNION RESULT 的 table 列的值为,1和2表示参与 union 的 select 行id。
type列表示MySQL使用哪种方式来查询数据,例如全表扫描、索引扫描等。下面是所有type列的取值及其含义的详细说明:
system:表示查询只有一行,并且该行是系统表中的行,这是最快的查询方式。
const:表示查询只有一行,并且该行可以通过索引进行访问,这也是最快的查询方式。
eq_ref:表示查询使用了连接操作,使用的是某个唯一性索引,例如主键或唯一索引。例如:
ref:表示查询使用了非唯一性索引进行访问,例如使用普通索引等。例如:
SELECT *
FROM table1
WHERE key_col = 'abc';
range:表示查询使用了索引范围查找,例如使用B-Tree索引等。例如:
SELECT *
FROM table1
WHERE key_col BETWEEN 10 AND 20;
index:表示查询使用了全索引扫描,即扫描整个索引,而不是扫描整个表。例如:
SELECT *
FROM table1
WHERE key_col LIKE 'abc%';
all:表示查询使用了全表扫描,即扫描整个表,这是最慢的查询方式。例如:
SELECT *
FROM table1;
unique_subquery:表示查询使用了子查询来获取唯一的索引值。例如:
SELECT *
FROM table1
WHERE key_col = (SELECT key_col2 FROM table2 WHERE id = 1);
index_subquery:表示查询使用了子查询来获取索引值,但是不一定唯一。例如:
SELECT *
FROM table1
WHERE key_col IN (SELECT key_col2 FROM table2 WHERE id > 100);
Extra列的取值包括很多种情况,以下是一些常见的Extra列取值及其含义:
Using index:表示MySQL使用了覆盖索引,即只使用了索引的信息而不需要访问表中的数据。这是一种高效的查询方式,可以减少MySQL的查询开销。Using temporary:表示MySQL需要创建临时表来完成查询操作。这种情况通常出现在排序、GROUP BY、DISTINCT等操作中,可以通过优化查询语句来避免创建临时表,提高查询性能。Using filesort:表示MySQL需要使用文件排序算法来完成查询操作。这种情况通常出现在ORDER BY操作中,可以通过添加索引或者优化查询语句来避免文件排序,提高查询性能。Using join buffer:表示MySQL需要使用连接缓存区来完成连接操作。这种情况通常出现在多表连接操作中,可以通过适当调整join_buffer_size参数来优化连接缓存区的性能。Using where:表示MySQL需要使用WHERE子句来过滤数据。这种情况通常出现在使用了索引的情况下,可以通过添加更多的索引或者优化查询语句来避免WHERE过滤,提高查询性能。Using index condition:表示MySQL需要使用索引条件来过滤数据。这种情况通常出现在使用索引的情况下,但是需要使用更多的表达式来过滤数据,可以通过添加更多的索引或者优化查询语句来避免索引条件,提高查询性能。Using sort_union:表示MySQL需要使用联合排序算法来完成查询操作。这种情况通常出现在UNION操作中,可以通过优化查询语句来避免联合排序,提高查询性能。Using intersect:表示MySQL需要使用交集算法来完成查询操作。这种情况通常出现在INTERSECT操作中,可以通过优化查询语句来避免交集操作,提高查询性能。
索引的全值匹配指的是查询条件中使用索引列进行等值匹配的情况。例如,对于一个包含id和name两列的表,如果我们对id列添加了索引,那么以下查询条件中的id=1就是一个全值匹配:
SELECT *
FROM table1
WHERE id = 1;
在这个查询语句中,id=1就是一个全值匹配,因为它只匹配id列上的一个值。
如果查询条件中包含了索引列之外的列,那么就不是全值匹配。例如,以下查询条件中的name='abc'就不是一个全值匹配:
SELECT *
FROM table1
WHERE id = 1
AND name = 'abc';
在这个查询语句中,id=1是一个全值匹配,但是name='abc'不是全值匹配,因为它只匹配了name列上的一部分值。
需要注意的是,全值匹配并不仅仅指等于号,还包括IN、IS NULL等操作。例如,以下查询条件中的id IN (1, 2, 3)也是一个全值匹配:
SELECT *
FROM table1
WHERE id IN (1, 2, 3);
在这个查询语句中,id IN (1, 2, 3)也是一个全值匹配,因为它匹配了id列上的三个值
全值匹配是索引最有效的使用方式之一,可以提高查询性能。因为全值匹配可以直接使用索引的值,而不需要对数据表进行全表扫描。在查询语句中,应该尽量使用索引列进行全值匹配,避免使用模糊查询或者范围查询等操作,以充分利用索引提高查询性能。
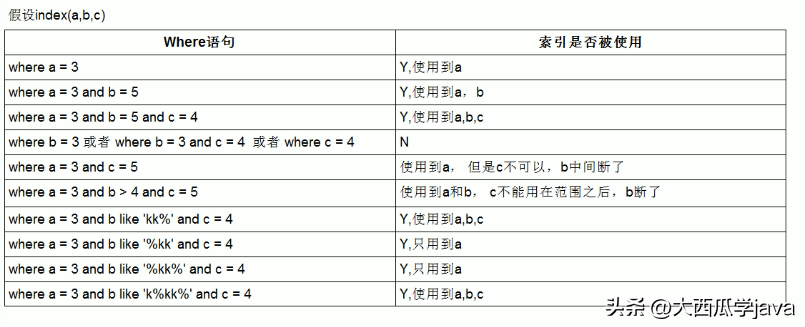
最左前缀法则是指在一个联合索引中,索引的最左前缀可以被用于查询中,而后面的部分则不能单独被使用。换句话说,如果一个查询只用到了联合索引的最左前缀,那么这个查询就可以使用联合索引进行优化,否则就无法使用联合索引。
举个例子,假设有一个包含三列id、name、age的表,我们对(id, name, age)这个联合索引进行了优化。对于以下查询语句:
SELECT *
FROM table1
WHERE id = 1;
可以使用联合索引进行优化,因为id是联合索引的最左前缀,只用到了id这一列。如果查询语句改成以下形式:
SELECT *
FROM table1
WHERE name = 'abc';
那么就无法使用联合索引进行优化,因为name不是联合索引的最左前缀,需要对整个表进行扫描。
需要注意的是,最左前缀法则只适用于联合索引,而不适用于单列索引。如果只有一个单列索引,那么可以使用这个索引进行任意的查询优化。
最左前缀法则是MySQL中索引优化的重要概念,需要在索引设计和查询优化时加以考虑。在设计联合索引时,需要根据实际情况选择适当的列进行索引,以充分利用最左前缀法则提高查询性能。
当查询条件涉及到对索引列进行计算、函数、类型转换等操作时,MySQL就无法使用索引进行优化,而只能进行全表扫描,这也被称为“索引失效”。
举个例子,假设有一个包含三列id、name、age的表,我们对id列添加了索引,以下查询语句可以使用索引进行优化:
SELECT *
FROM table1
WHERE id = 1;
在这个查询语句中,查询条件直接使用了id列,没有进行任何计算、函数、类型转换等操作,因此MySQL可以使用索引进行优化,避免全表扫描。
但是,如果查询条件对id列进行了计算、函数、类型转换等操作,那么MySQL就无法使用索引进行优化,只能进行全表扫描。例如,以下查询语句就无法使用索引进行优化:
SELECT *
FROM table1
WHERE id 1 = 2;
在这个查询语句中,查询条件对id列进行了计算,MySQL无法使用索引进行优化,只能进行全表扫描。
因此,在进行查询优化时,需要尽量避免在查询条件中对索引列进行计算、函数、类型转换等操作,以充分利用索引提高查询性能。如果无法避免这些操作,可以考虑对数据表进行优化,例如将计算、函数、类型转换等操作的结果存储到新的列中,并对新的列添加索引。
尽量使用覆盖索引可以有效减少查询的数据量,提高查询性能。覆盖索引是指查询语句只需要访问索引,而不需要访问数据表就可以得到所需的结果。
举个例子,假设有一个包含三列id、name、age的表,我们对id和name两列添加了联合索引。以下查询语句需要查询id和name两列:
SELECT id, name
FROM table1;
这个查询语句并没有使用WHERE条件,如果使用普通索引,MySQL会通过索引查找到对应的数据行,然后再根据需要的列进行读取。但是如果使用覆盖索引,MySQL可以直接从索引中获取id和name两列的值,而不需要再进行数据表的访问,大大提高了查询性能。
但是,需要注意的是,并不是所有的查询都可以使用覆盖索引。如果查询语句需要返回数据表中的大量列,那么使用覆盖索引反而会降低查询性能,因为MySQL需要在索引和数据表之间来回切换。因此,在查询优化时,需要根据具体情况选择是否使用覆盖索引。
同时,需要尽量避免使用SELECT *语句,因为这个语句会查询数据表中的所有列,无法使用覆盖索引进行优化,而且也会导致查询数据量过大,降低查询性能。在实际使用中,建议根据具体需求选择需要的列进行查询,避免使用SELECT *语句。
综上所述,尽量使用覆盖索引可以提高查询性能,但需要根据具体情况进行权衡和选择。同时,需要避免使用SELECT *语句,选择需要的列进行查询。
在MySQL中,当使用字符串进行查询时,如果字符串不加单引号,MySQL会将它视为列名或关键字,而不是字符串字面值,因此无法使用索引进行优化,会导致索引失效。
尽可能的使用索引,减少全表扫描;在设计表结构时,需要考虑查询的需求,并选择合适的索引类型;使用最左前缀法则,建立符合查询需求的复合索引;避免在查询条件中对索引列进行计算、函数、类型转换等操作,以充分利用索引提高查询性能;尽量使用覆盖索引,减少SELECT *等语句的使用;使用字符串进行查询时,需要注意加上单引号,以充分利用索引提高查询性能;避免在索引列上进行UPDATE、DELETE等操作,以免造成索引失效;对于长字符串类型的列,需要使用前缀索引或全文索引来优化查询性能;定期维护索引,对于不再使用的索引,可以考虑删除以减少索引维护成本。
人类能移居到别星球吗(不能)
人类目前还不能移居到别的星球。近年来,科学家们发现了一颗距离地球约600光年的行星,被冠以“超级地球”的称号。这颗行星名为开普勒22b(Kepler-22b),位于天鹅座,被认为可能具备一定的宜居条件。我要新鲜事2024-01-08 21:17:000000离地球最近的中子星,250-1000光年(进入太阳系将毁灭地球)
作为宇宙中最危险的天体,中子星大家应该不陌生,它被称为黑洞的儿子,具有极强的破坏性。知道中子星后,许多人都好奇:离地球最近的中子星是哪个?今天小编就来为大家好好讲解一下。一、离地球最近的中子星1、卡尔维拉我要新鲜事2023-05-11 03:34:250008宇宙有多少恒星?可能有一千亿亿颗(可观测范围内)
解答:人们可以观测到的宇宙范围只有930亿光年,同时研究发现可以观测到的宇宙中最少有一千亿个星系,而每个星系中可能包含着一亿个恒星,所以宇宙中大约有一千亿亿颗恒星。银河系有多少恒星?我要新鲜事2023-05-10 08:41:210000超巨星的基本情况 超巨星的重要特点
导语:超巨星是质量最大的恒星,主要位于赫罗图最顶端的位置,一般被分为两种,炙热的红超巨星和寒冷的蓝超巨星,超巨星的质量是太阳的5至150倍,亮度最少是太阳亮度的两千倍到数百万倍不等,超巨星的光谱几乎占据所有的类型,但状态较不稳定,大部分都有光变的特性,下面和探秘志共同了解下超巨星吧。超巨星的基本情况我要新鲜事2023-05-09 22:57:130000人类的大脑逐渐缩小 是不是智力也会下降(人类智力)
人类的大脑缩小,不代表智商会减弱。我们人类之所以可以站在地球之巅,就是因为人类有着聪明的大脑,有着相对比较高的智商,通过人类的聪明才智可以创造出很多为我们所用的工具,让人类不光可以在陆地上飞快的奔跑,也可以上天下海,可以说如果人类没有聪明智商的话,那绝对不会成为现在食物链顶端的样子。1.智力下降我要新鲜事2023-08-06 20:29:090000